В данной статье мы исследуем различные способы установки TCP-соединений и увидим, что широко известное трёхстороннее рукопожатие — не единственный способ. Узнаем, как TCP-соединение может быть установлено с самим собой. Пробежимся по некоторым основам TCP, поговорим про эфемерные порты и как TCP может быть ненадёжным. Испробуем в деле tcpdump, netem и NFQUEUE. Используя Scapy, напишем несколько собственных серверов, которые будут самостоятельно обмениваться сообщениями по протоколу TCP и осуществлять различные виды установки соединения.
Немного о TCP Ссылка на заголовок
TCP предоставляет пользователю протокола (достаточно) надёжный, полнодуплексный, потоковый сервис передачи байтов. Разберём, что это значит:
- Полнодуплексный означает, что в любой момент времени обе стороны могут одновременно отправлять и получать данные. Иными словами, оба направления независимы друг от друга. Противоположностью является полудуплексное соединение, при котором стороны должны передавать данные по очереди, а также симплексное, при котором передача может идти только в одном направлении.
- Потоковый сервис означает, что пользователь TCP получает возможность передавать и получать некоторое количество байт от собеседника в том порядке, в котором они были отправлены. Разделение этой последовательности байт на логические части — например на сообщения протокола более высокого уровня — возлагается на пользователя протокола.
- Почему TCP достаточно надёжен описано в конце раздела.
Первоначальная спецификация TCP — RFC 793 от 1981 года — теперь считается устаревшей, более новая редакция — RFC 9293 от 2022 года — содержит накопившиеся с 1981 года дополнения.
Для того, чтобы иметь несколько точек назначения на одном хосте, TCP использует беззнаковые 16-битные порты: следовательно, максимальный номер порта — 65535. Это также позволяет иметь несколько TCP-соединений между одной парой хостов.
Сообщения протокола TCP называются сегментами. Они состоят из заголовка — служебной информации, необходимой для работы TCP — и полезной нагрузки (payload) — некоторой непрерывной части последовательности байт, передаваемой пользователем протокола. Каждому байту полезной нагрузки присваивается свой порядковый номер, причём нумерация ведётся независимо в каждом направлении — от клиента к серверу и от сервера к клиенту. Такая нумерация позволяет:
- отслеживать, какие части данных успешно приняты другой стороной и переотправлять данные, которые не были получены;
- восстанавливать исходный порядок сегментов, пришедших не по порядку;
- определять дубликаты одного и того же сегмента;
Следовательно, каждый сегмент, содержащий полезную нагрузку, указывает номер первого байта той части полезной нагрузки, которая содержится в сегменте. Можно было бы предположить, что нумерация начинается с 0 или 1, однако это не так. Использование разных значений в качестве «точки отсчёта» усложняет/предотвращает ряд атак, в которых злоумышленнику необходимо угадать номера байт, которые одна из сторон ожидает. Если последовательность «точек отсчёта» будет вдобавок возрастающей, можно будет решить ещё одну проблему: можно будет отличить сегмент из текущего соединения от сегмента, отправленного в рамках предыдущего соединения, и по различным причинам «затерявшегося» в сети и пришедшего лишь спустя какое-то время.
При установке соединения и сервер, и клиент выбирают свой ISN (Initial Sequence Number, Начальный Порядковый Номер) — 32-битное беззнаковое число, определяющее нумерацию передаваемых ими байт. Это та самая «точка отсчёта»; иными словами — номер нулевого байта. Первый байт переданной полезной нагрузки будет иметь номер ISN + 1, второй — ISN + 2 и так далее (всё по модулю 2^32). При установке соединения выбранный ISN сообщается другой стороне.
Больше информации о ISN, алгоритме его генерации и атаках на ISN в RFC 6528: Defending Against Sequence Number Attacks.
Заголовок TCP‑сегмента, помимо прочего, содержит:
- 32-битное поле Sequence Number (Порядковый Номер,
Seq), содержащее номер первого байта полезной нагрузки данного сегмента. - 32-битное поле Acknowledgment Number (Номер Подтверждения,
Ack) — отправитель сегмента в данном поле указывает номер первого байта, который ещё не был получен от другой стороны. Использует нумерацию собеседника.
Заголовки TCP‑сегментов также содержат набор флагов (булевых значений). В контексте данной статьи нас интересуют следующие:
SYN(synchronize sequence numbers — синхронизировать порядковые номера). Данный флаг устанавливает семантику поляSEQ: если флаг установлен, то полеSeqсодержит ISN. В противном случае, полеSeqсодержит номер первого байта данных, которые содержит сегмент.ACK(acknowledgment field is significant — полеAckзадействовано). Данный флаг устанавливает семантику поляAck: если флаг установлен, то полеAckсодержит значение. В противном случае, считаем, что значение поляAckне устанавливалось и содержит произвольное значение.
Почему TCP был упомянут как в целом надёжный, а не просто надёжный? Обычно, когда пишут что «TCP надёжный», имеют в виду надёжную доставку сегментов получателю: TCP решает перечисленные выше проблемы, тогда как протоколы нижних уровней их не решают.
Однако в обеспечении целостности данных есть некоторые «шероховатости». Для проверки того, что отправленные данные не были случайно изменены, TCP использует 16-битную контрольную сумму — по современным стандартам весьма слабую. Поскольку в Ethernet используется намного более надёжный
CRC32, вероятность того, что повреждённые данные пройдут обе проверки, остаётся очень низкой (в IP целостность полезной нагрузки не проверяется вовсе). И всё же, эта вероятность значительно выше, чем вероятность случайной коллизии в современных криптографических хеш-функциях: того же, в данный момент уставшего,MD5или других. Кроме того, существует риск того, что данные, успешно прошедшие проверкуCRC32, могут быть повреждены из-за ошибки в программном обеспечении протоколов (как, например, произошло в Twitter).Что же с этим делать? Можно просто использовать применяющий криптографию TLS. Если же целостность необходимо обеспечивать в разрабатываемых протоколах, то для проверки целостности данных можно применять криптографические хеш-функции, например
SHA-256, или более лёгкие контрольные суммы, такие какCRC32C. Да и в целом, end-to-end проверки целостности данных — это хорошая практика.Что ещё почитать на эту тему:
- When the CRC and TCP checksum disagree;
- TCP Checksums are not enough — +1 за упоминание e2e проверок целостности данных в Google Chubby;
- CorfuDB: Argument for end-to-end data integrity — некоторое количество литературы для дальнейшего чтения.
Примечание: данная статья не затрагивает расширения TCP, например, TCP Fast Open.
Для запуска команд и программ, описанных в статье, использовались Docker-контейнеры на базе Debian 12 с ядром Linux
6.8.0-58-generic.
3-way handshake Ссылка на заголовок
Handshake (рукопожатие) — процесс обмена сообщениями с целью установки соединения между двумя хостами. Это необходимо для предварительной установки и согласования различных параметров.
Сторона, которая отправляет первый TCP‑сегмент, тем самым инициируя процедуру установки соединения, называется клиентом. Сторона, которая ожидает первый сегмент от другой стороны, называется сервером. Иными словами, клиент осуществляет активное открытие соединения, а сервер — пассивное. [2]
Трёхстороннее рукопожатие (3-way handshake, 3WHS) — это то, как на практике происходит установка TCP-соединения в подавляющем большинстве случаев (~всегда). Трёхстороннее оно потому, что успешная установка TCP-соединения происходит за три сегмента:
- Клиент отправляет серверу сегмент с установленным флагом
SYNи своим сгенерированнымISN, записанным в полеSeq. - Сервер отвечает сегментом с установленными флагами
SYNиACK, полемSeqсодержащим своё сгенерированное значениеISN. В качестве подтверждения того, что приём предыдущего сегмента прошел успешно, этот сегмент также содержит числовое значение в полеAckравноеISN клиента + 1. - Клиент отвечает серверу сегментом c указанным в поле
AckзначениемISN сервера + 1и установленным флагомACK.
Посмотрим, как это выглядит на практике. Сделаем тестовый стенд в Docker, состоящий из следующих сервисов:
- клиент — Отправляет HTTP
GET-запрос к серверу (в полезной нагрузке TCP) и выводит на экран тело полученного от сервера HTTP-ответа. В качестве клиента используемcurl. - сервер — Ожидает подключения на порту
8000. После успешного подключения отправляет HTTP-ответ (в качестве полезной нагрузки TCP). - наблюдатель — Наблюдает за
TCP-сегментами, которыми обмениваются клиент и сервер, и выводит их на экран. Используемtcpdump.
Для начала посмотрим, как обычно происходит коммуникация между клиентом и сервером. Для этого используем стандартную библиотеку сокетов и, таким образом, реализацию TCP операционной системы. Делаем bind, listen, accept и отправляем HTTP-ответ:
import socket
def create_http_response(body: str) -> bytes:
template = f"""HTTP/1.1 200 OK\r
Connection: close\r
Content-Length: {len(body)}\r
Content-Type: text/html\r
Host: server\r
\r
{body}"""
return template.encode("ascii")
if __name__ == "__main__":
# SOCK_STREAM - значит использовать TCP (stream - поток, т.к. потоковый сервис)
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind(("0.0.0.0", 8000))
s.listen(1)
conn, _ = s.accept()
with conn:
# Отправляем HTTP-ответ через TCP.
conn.sendall(create_http_response("Hello from the default server!"))
Смотрим на вывод tcpdump:
15:12:20.742145 IP split-handshake-client-1.split-handshake_default.56016 > df4e7823c0b4.8000: Flags [S], seq 3088454448, win 64240, options [mss 1460,sackOK,TS val 592953866 ecr 0,nop,wscale 7], length 0
15:12:20.742197 IP df4e7823c0b4.8000 > split-handshake-client-1.split-handshake_default.56016: Flags [S.], seq 3878989831, ack 3088454449, win 65160, options [mss 1460,sackOK,TS val 140002617 ecr 592953866,nop,wscale 7], length 0
15:12:20.742252 IP split-handshake-client-1.split-handshake_default.56016 > df4e7823c0b4.8000: Flags [.], ack 3878989832, win 502, options [nop,nop,TS val 592953866 ecr 140002617], length 0
15:12:20.742423 IP split-handshake-client-1.split-handshake_default.56016 > df4e7823c0b4.8000: Flags [P.], seq 3088454449:3088454524, ack 3878989832, win 502, options [nop,nop,TS val 592953866 ecr 140002617], length 75
15:12:20.742448 IP df4e7823c0b4.8000 > split-handshake-client-1.split-handshake_default.56016: Flags [.], ack 3088454524, win 509, options [nop,nop,TS val 140002617 ecr 592953866], length 0
15:12:20.742543 IP df4e7823c0b4.8000 > split-handshake-client-1.split-handshake_default.56016: Flags [P.], seq 3878989832:3878989953, ack 3088454524, win 509, options [nop,nop,TS val 140002617 ecr 592953866], length 121
15:12:20.742606 IP split-handshake-client-1.split-handshake_default.56016 > df4e7823c0b4.8000: Flags [.], ack 3878989953, win 502, options [nop,nop,TS val 592953866 ecr 140002617], length 0
15:12:20.742674 IP df4e7823c0b4.8000 > split-handshake-client-1.split-handshake_default.56016: Flags [R.], seq 3878989953, ack 3088454524, win 509, options [nop,nop,TS val 140002617 ecr 592953866], length 0
tcpdump: pcap_loop: The interface disappeared
8 packets captured
8 packets received by filter
0 packets dropped by kernel
Уберём сообщения лога, которые не связаны с установкой соединения, а также сделаем ещё немного манипуляций, чтобы лог получился более удобочитаемым:
client > server: Flags [S], seq 3088454448
server > client: Flags [SA], seq 3878989831, ack 3088454449
client > server: Flags [A], ack 3878989832
Flags [...] содержит обозначения флагов, установленных в перехваченном сегменте. S означает флаг SYN, а A — флаг ACK.
Теперь напишем собственный сервер, который не будет использовать системную реализацию TCP, а будет самостоятельно выполнять трёхстороннее рукопожатие и отправлять наше HTTP-сообщение. Чтобы иметь возможность отправлять TCP‑сегменты напрямую, нужно спуститься хотя бы на один уровень ниже — до уровня IP и отправлять IP-пакеты, содержащие TCP‑сегменты в качестве своей полезной нагрузки.
Мы будем принимать и обрабатывать входящие TCP‑сегменты с помощью библиотеки Scapy. Вместо Scapy, можно было бы напрямую работать с raw-сокетами для работы с IP-пакетами, однако Scapy предоставляет удобный интерфейс для различных манипуляций с пакетами и сегментами.
Операционная система не знает о том, что мы собираемся делать, поэтому, когда на закрытый (с точки зрения TCP-стека ОС) порт приходит сегмент, она отправляет в ответ сегмент с флагом RST, информируя, что соединение установить невозможно. Нам это поведение не подходит: наш сервер будет самостоятельно заниматься обработкой сегментов и мы не хотим, чтобы системная реализация TCP вмешивалась. Для решения данной проблемы установим «молчаливую» фильтрацию сегментов фаерволом. Наше приложение будет видеть данные сегменты, а TCP-стек ОС их видеть не будет.
iptables -t raw -I PREROUTING -p tcp --dport 8000 -j DROP
iptables -t raw -I OUTPUT -p tcp --sport 8000 -j DROP
Данные правила устанавливают «молчаливую» фильтрацию сегментов, которые содержат порт 8000 в качестве порта отправителя либо порта получателя. Поскольку правила заданы в таблице raw, они срабатывают до стека TCP.
Здесь и далее реализации серверов содержат минимальное количество кода и функционала, необходимое для установки TCP-соединения и отправки данных. Вот список из некоторых сделанных упрощений:
- игнорируются все входящие сегменты после установки соединения;
- сразу после установки соединения, не дожидаясь HTTP-запроса, сервер отправляет TCP‑сегмент, содержащий HTTP-ответ;
- не реализуется больша́я (и бо́льшая) часть протокола TCP — в том числе не происходит «любезное» (graceful) завершение соединения;
- ISN генерируется полностью случайно;
- одновременно может работать не более чем с одним клиентом;
- не обрабатываем случаи, когда в сегменте установлены флаги, которых мы не ожидаем.
Всё для того, чтобы иметь минимальный код и сосредоточиться только на процедуре установки TCP-соединения.
Отправляемый сервером HTTP-ответ позволяет открыть в браузере URL http://localhost:8000 и получить наглядное подтверждение того, что соединение установлено и работает.
Код сервера, осуществляющего трёхстороннее рукопожатие:
import ctypes
import random
from scapy.layers.inet import TCP, IP
from scapy.sendrecv import send, sniff
from scapy.packet import Packet, Raw
# Значения, большие 2**32, будут взяты по модулю 2**32.
def uint32(x: int) -> int:
return ctypes.c_uint32(x).value
def create_http_response(body: str) -> bytes:
template = f"""HTTP/1.1 200 OK\r
Connection: close\r
Content-Length: {len(body)}\r
Content-Type: text/html\r
Host: server\r
\r
{body}"""
return template.encode("ascii")
class Server:
def run(self) -> None:
sniff(iface="eth0", prn=self.handle_packet, filter=f"tcp dst port 8000", store=0)
def handle_packet(self, p: Packet) -> None:
# Смотрим, с какими флагами нам пришёл TCP‑сегмент.
fs = set(p[TCP].flags)
if fs == {"S"}: # SYN
self._connection_established = False
self._isn = random.randint(0, 2**32 - 1)
self._reply(
p,
flags="SA",
ack=uint32(p[TCP].seq + 1),
seq=self._isn,
)
elif fs == { "A" }: # ACK
if self._connection_established:
return
self._connection_established = True
# Отправляем полезную нагрузку.
self._reply(
p,
create_http_response("Hello from the 3-way handshake TCP server!"),
flags="PA", # PSH-ACK. PSH просит получателя не буферизировать данный сегмент.
ack=p[TCP].seq,
seq=uint32(self._isn + 1),
)
def _reply(self, p: Packet, payload: bytes = b"", **kwargs) -> None:
il = IP(src=p[IP].dst, dst=p[IP].src)
tl = TCP(
sport=p[TCP].dport,
dport=p[TCP].sport,
**kwargs,
)
send(il / tl / Raw(payload), verbose=False)
if __name__ == "__main__":
Server().run()
Смотрим упрощённую мной часть лога tcpdump, отвечающую за рукопожатие:
client > server: Flags [S], seq 1417278038
server > client: Flags [SA], seq 3093614128, ack 1417278039
client > server: Flags [A], ack 3093614129
То же самое, что и при системной реализации. Дополнительно, проверим работоспособность сервера подключившись через браузер:
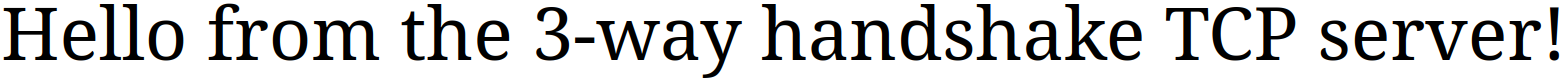
Одновременное открытие Ссылка на заголовок
Заглянем ещё раз в спецификацию TCP (цитаты здесь и далее в моём переводе):
Трёхстороннее рукопожатие — это процедура, используемая для установки соединения. Обычно она инициируется одним TCP-узлом, которому затем отвечает другой TCP-узел. Процедура также работает, если два TCP-узла инициируют её одновременно. При одновременной попытке установки соединения каждый из TCP-узлов получает SYN-сегмент, не содержащий подтверждения (ACK), после того как сам отправил SYN.
И ещё:
Одновременная инициация лишь немного более сложная:
TCP A TCP B 1. CLOSED CLOSED 2. SYN-SENT --> <SEQ=100><CTL=SYN> ... 3. SYN-RECEIVED <-- <SEQ=300><CTL=SYN> <-- SYN-SENT 4. ... <SEQ=100><CTL=SYN> --> SYN-RECEIVED 5. SYN-RECEIVED --> <SEQ=100><ACK=301><CTL=SYN,ACK> ... 6. ESTABLISHED <-- <SEQ=300><ACK=101><CTL=SYN,ACK> <-- SYN-RECEIVED 7. ... <SEQ=101><ACK=301><CTL=ACK> --> ESTABLISHED
Слева и справа на схеме указаны состояния (states) конечных автоматов TCP-узлов, которые для простоты опущены в данной статье. Посередине указаны флаги и значения полей Seq и Ack в отправляемых и принимаемых сегментах.
Итак, ещё один способ установки TCP-соединения — одновременное открытие. Оно происходит, когда оба узла отправляют SYN-сегмент, инициирующий установку соединения, другой стороне до того как примут SYN от другой стороны. В этом случае, установка соединения осуществляется за 4 сегмента:
A B
1. SYN -->
2. SYN <--
3-4. SYN,ACK -->
3-4. SYN,ACK <--
Отметим, что при таком способе установки соединения среди сторон не выделяется ни сервер, ни клиент, так как обе стороны осуществляют активное открытие. Поэтому, в данном случае они обозначены как A и B. [2]
Такой способ установки TCP-соединения осуществляется крайне редко, поскольку обе стороны должны заранее знать IP-адрес и TCP-порт друг друга. В обычной ситуации клиенту известны адрес и порт сервера, а сервер узнаёт адрес и порт клиента из полученного от него сегмента. Одновременное открытие применяется, например, при TCP hole punching. [2] В двух словах, и A, и B отправляют сегмент SYN друг другу, что позволяет NAT каждого разрешить входящие сообщения на соответствующие порты — и таким образом установить TCP-соединение между узлами за NAT.
Попробуем осуществить одновременное открытие соединения. Запустим два приложения, каждое из которых будет выполнять connect к другому и отправлять некоторую полезную нагрузку. Обычно перед выполнением connect TCP-порт отправителя явным образом не указывается и выбирается TCP-стеком ОС из пула эфемерных портов (подробнее об этом в следующем разделе). Однако, в нашем случае адреса и порты должны быть известны заранее, поэтому эфемерный порт нам не подходит. Необходимо предварительно выполнить bind на определённый адрес и порт.
Для того, чтобы каждое приложение отправило SYN до того, как получит на него ответ, воспользуемся netem и добавим задержку в 400 миллисекунд на доставку каждого TCP‑сегмента:
tc qdisc add dev lo root handle 1:0 netem delay 400ms
Для того, чтобы выполнить данную команду в Docker контейнере, нужно добавить флаг
--cap-add=NET_ADMINили--privilegedк командеdocker run(илиdocker exec).
Для удаления задержки можно использовать
tc qdisc del dev lo root
Благодаря задержке на доставку, оба клиента отправят свой SYN-сегмент и получат сегмент от другой стороны как минимум через 400мс. Как раз то, что нужно для одновременного открытия. Задержка в 400мс была подобрана эмпирически. Бо́льшая величина задержки может привести к переотправке сегментов из-за отсутствия подтверждения их принятия в течение некоторого времени.
В качестве коммуницирующего приложения будем использовать nc (netcat):
nc -p 2000 127.0.0.1 3000 & nc -p 3000 127.0.0.1 2000 &
Флаг -p ЧИСЛО задаёт номер порта отправителя — это означает, что перед вызовом connect netcat сделает bind на локальный IP-адрес и указанный TCP-порт.
Для перехвата пакетов на интерфейсе loopback выполним tcpdump -i lo. Итого: добавляем задержку с помощью netem, запускаем оба экземпляра nc и наблюдаем следующий (упрощённый мной) вывод tcpdump:
A > B: Flags [S], seq 2472141684
B > A: Flags [S], seq 2303140715
B > A: Flags [SA], seq 2303140715, ack 2472141685
A > B: Flags [SA], seq 2472141684, ack 2303140716
A > B: Flags [A], ack 2303140716
B > A: Flags [A], ack 2472141685
Первые четыре сегмента (отделены пустой строкой) — это одновременное открытие (simultaneous open), как и описано в RFC. Два последующих сегмента ACK не играют роли при установке соединения, хоть и отправляются реализацией TCP в ядре Linux. Проверим это утверждение. Действительно ли 2 сегмента ACK, отправляемые после того, как simultaneous open завершено согласно спецификации, не являются частью рукопожатия? Может быть, ACK необходим и реализация протокола не является соответствующей спецификации?
Для того, чтобы разобраться, отбросим все сегменты от каждой из сторон, которые выполняют одновременное открытие, идущие после SYN и SYN-ACK сегментов. Затем проверим, находится ли соединение в состоянии «установлено»: если соединение считается установленным в обоих контейнерах, то ACK не играет роли в установке соединения. В противном случае — это часть рукопожатия.
В нашем тестовом стенде будет следующие сервисы:
A,B— два приложения, которые делаютbindна определённые порты на локальном хосту, после чего каждое приложение пытается подключиться к другому.- перехватчик (
interceptor) — данный сервис перехватывает все сегменты, пересылаемые междуAиBи удерживает каждый сегмент, пока не появится сегмент в обратном направлении; после этого пара сегментов (один отAкBи один отBкA) выпускается (практически) одновременно. Нас интересуют только сегменты, входящие в одновременное открытие, поэтому все сегменты кромеSYNиSYN-ACKбудут отбрасываться. То есть, практически одновременно будут отправлены перехваченные сегментыSYNотAкBи отBкA. Аналогично сSYN-ACK. - наблюдатель — ещё раз используем
tcpdump.
Контейнеры A и B располагаются в разных сетях для того, чтобы они использовали для коммуникации сетевой шлюз по умолчанию (default gateway), которым будет наш перехватчик. Иными словами, перехватчик стоит между A и B. Для того, чтобы манипулировать сегментами, в контейнере с interceptor-ом, при помощи iptables перенаправляем все входящие и исходящие сегменты в NFQUEUE. Таким образом, все сегменты будут остановлены. Пропустить далее к адресату или отбросить сегменты будет решать Python-скрипт, работающий с NFQUEUE через библиотеку netfilterqueue и реализующий логику попарной отправки, описанную выше. Приведём код перехватчика (interceptor):
#!/usr/bin/env python3
import os
from netfilterqueue import NetfilterQueue
from scapy.layers.inet import TCP, IP
SIDE_A_IP = os.environ["SIDE_A_IP"]
SIDE_A_PORT = int(os.environ["SIDE_A_PORT"])
SIDE_B_IP = os.environ["SIDE_B_IP"]
SIDE_B_PORT = int(os.environ["SIDE_B_PORT"])
buffer = {"a2b": [], "b2a": []}
def cb(packet) -> None:
sc = packet.get_payload()
il = IP(sc)
tl = il[TCP]
key = ""
if (
il.src == SIDE_A_IP
and tl.sport == SIDE_A_PORT
and il.dst == SIDE_B_IP
and tl.dport == SIDE_B_PORT
):
key = "a2b"
elif (
il.src == SIDE_B_IP
and tl.sport == SIDE_B_PORT
and il.dst == SIDE_A_IP
and tl.dport == SIDE_A_PORT
):
key = "b2a"
else:
# Пропускаем дальше сегмент, который идёт не между A и B.
packet.accept()
return
# Не пропускаем сегменты, кроме SYN и SYN-ACK.
fs = set(tl.flags)
if fs != {"S"} and fs != {"S", "A"}:
return
packet.retain()
buffer[key].append(packet)
try_release_in_pairs()
def log_str(packet) -> str:
scapy_packet = IP(packet.get_payload())
return str(scapy_packet)
def try_release_in_pairs() -> None:
while buffer["a2b"] and buffer["b2a"]:
p1 = buffer["a2b"][0]
p2 = buffer["b2a"][0]
buffer["a2b"] = buffer["a2b"][1:]
buffer["b2a"] = buffer["b2a"][1:]
print(f"Releasing 2 packets: {log_str(p1)} and {log_str(p2)}.", flush=True)
p1.accept()
p2.accept()
if __name__ == "__main__":
print("Creating a queue.", flush=True)
nfq = NetfilterQueue()
nfq.bind(1, cb)
print("Running filter.", flush=True)
try:
nfq.run()
finally:
nfq.unbind()
Посмотрим на упрощённые мной логи tcpdump:
15:34:33.063076 A > B: Flags [S], seq 416807200
15:34:33.063124 B > A: Flags [S], seq 2087524263
15:34:33.064385 A > B: Flags [SA], seq 416807200, ack 2087524264
15:34:33.064433 B > A: Flags [SA], seq 2087524263, ack 416807201
Видно, что оба сегмента SYN отправляются практически одновременно; аналогично SYN-ACK. Других сегментов отправлено не было.
Проверим статус сокета в контейнерах A и B:
$ ss -tan
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 172.28.1.10:27777 172.29.1.10:27778
$ ss -tan
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 172.29.1.10:27778 172.28.1.10:27777
Соединение находится в состоянии установлено (ESTABlished), хотя ни одного сегмента кроме SYN и SYN-ACK не было отправлено. Это подтверждает утверждение о том, что дополнительные ACK, посылаемые реализацией TCP в ядре Linux, не требуются для самой установки соединения. Ещё раз подытожим: Linux поддерживает одновременное открытие соединения, которое, согласно спецификации, — это SYN и SYN-ACK в обоих направлениях, несмотря на то, что Linux-реализацией в обоих направлениях отправляются SYN, SYN-ACK и ACK.
Разговариваем с собой Ссылка на заголовок
Рассмотрим следующий Bash-скрипт:
while true
do
telnet 127.0.0.1 50000
done
Здесь мы пытаемся подключиться на порт 50000 на локальном хосте. Если подключение не удалось, пробуем ещё раз. В случае успешного подключения telnet сообщает об этом в терминале и открывает интерактивную сессию. Перед запуском скрипта порт 50000 закрыт.
Если дать скрипту поработать, то (скорее всего, после серии неудачных попыток) подключение всё же будет установлено:
telnet: can't connect to remote host (127.0.0.1): Connection refused
telnet: can't connect to remote host (127.0.0.1): Connection refused
telnet: can't connect to remote host (127.0.0.1): Connection refused
[ много одинаковых строк ]
telnet: can't connect to remote host (127.0.0.1): Connection refused
telnet: can't connect to remote host (127.0.0.1): Connection refused
Connected to 127.0.0.1
Попробуем что-нибудь отправить:
Connected to 127.0.0.1
Hello there.
Hello there.
Итак, подключение установлено. Отправляемые сообщения приходят обратно к нам. Портом 50000 кроме нас никто не пользовался. Всё указывает на то, что мы подключились сами к себе! Как это произошло?
Рассмотрим псевдокод, описывающий, как обычно происходит подготовка сокета на сервере:
s = socket()
bind(s, IP_АДРЕС, TCP_ПОРТ)
listen(s)
cs = accept(s)
# Сокет cs готов к использованию.
IP_АДРЕС указывает интерфейс, на котором нужно принимать входящие подключения: например 127.0.0.1, 0.0.0.0, 192.168.1.2 или другие. Обычно, TCP_ПОРТ — это некоторая ненулевая константа, заранее известная и серверу и клиенту. При запуске сервер резервирует данный порт и ожидает подключения клиентов на этот порт на указанном интерфейсе.
Теперь рассмотрим псевдокод того, как обычно происходит подготовка сокета на клиенте:
s = socket()
connect(s, IP_АДРЕС, TCP_ПОРТ)
# Сокет s готов к использованию.
При подключении клиент знает на какой TCP порт нужно подключаться. При этом ему, как правило, не важно с какого порта будет осуществляться соединение. В псевдокоде выше операционная система сама назначит порт для данного сокета, выбрав его из пула эфемерных портов — диапазона номеров портов, выделенных для краткоживущих соединений. Противоположностью этому являются, например, зарезервированные порты или заранее согласованный сервером или клиентом порт. При закрытии сокета эфемерный порт будет вновь доступен для других сокетов, которым нужен эфемерный порт.
Частота появления слова «обычно» подразумевает, что псевдокоды клиента и сервера отображают то как чаще всего происходит работа с сокетами на сервере и клиенте. В принципе, логика может быть несколько другой. Так, например, серверу не обязательно делать
bindна заранее определённый TCP-порт: можно использовать порт0, в этом случае операционная система присвоит эфемерный порт, на котором сервер будет слушать. Номер присвоенного порта нужно будет узнать используяgetsockoptи каким-либо образом сообщить клиенту. Клиент также может использовать несколько другую логику и использоватьbindдля того, чтобы устанавливать активное подключение с определённого порта.
Операционная система перебирает диапазон эфемерных портов некоторым случайным образом [3][4]. Поиск заканчивается, если был найден незанятый порт или все порты были проверены и заняты. Стоит отметить, что в целях оптимизации (для уменьшения contention между вызовами connect и bind), при вызове connect предпочтение отдаётся портам с чётными номерами, используя нечётные только в случае, если все чётные порты были заняты. [4] [5]
На Linux-системах узнать свой диапазон эфемерных портов можно выполнив
cat /proc/sys/net/ipv4/ip_local_port_range.
Таким образом — это лишь вопрос времени когда telnet будет использовать порт 50000 для активного подключения к порту 50000 на локальном хосте. Далее, при выполнении connect будет отправлен сегмент SYN, который будет принят тем же сокетом. Мы отправили SYN-сегмент и, не получив на него ответ SYN-ACK, получаем SYN-сегмент от «собеседника». Получается, telnet ведёт себя как участник одновременного открытия соединения! Далее отправляем и получаем от себя же SYN-ACK, и соединение установлено. Все последующие отправленные сегменты также будут приходить обратно, следовательно вся отправленная полезная нагрузка приходит обратно в telnet.
Разделённое рукопожатие Ссылка на заголовок
Заглянем в RFC 9293 и увидим следующее (в моём переводе):
Для синхронизации каждая сторона должна отправить свой начальный номер последовательности и получить его подтверждение (ACK) от другой стороны. Каждая сторона также должна получить начальный номер последовательности противоположной стороны и отправить подтверждение его приёма.
1) A --> B SYN: мой ISN X
2) A <-- B ACK: твой ISN X
3) A <-- B SYN: мой ISN Y
4) A --> B ACK: твой ISN Y
Поскольку шаги 2 и 3 могут быть объединены в одном сообщении, это называется трёхсторонним рукопожатием (или рукопожатием из трёх сообщений, 3WHS).
По сути, трёхстороннее рукопожатие осуществляет четыре логических действия, как и изображено на схеме. Давайте попробуем разделить сегмент SYN-ACK и отправить два отдельных сегмента: ACK и SYN. По сути, это уже не является соответствующим спецификации сервером, поскольку RFC чётко предписывает отправлять SYN-ACK в ответ на входящий SYN. Всё же проверим, как поведёт себя клиент.
Далее идёт часть кода, которая изменилась в 3-way handshake сервере:
def handle_packet(self, p: Packet) -> None:
# Смотрим с какими флагами нам пришёл TCP‑сегмент.
fs = set(p[TCP].flags)
if fs == { "S" }: # SYN
self._connection_established = False
self._isn = random.randint(0, 2**32 - 1)
self._reply(
p,
flags="A",
ack=uint32(p[TCP].seq + 1),
)
self._reply(p, flags="S", seq=self._isn)
elif fs == { "A" }: # ACK
if self._connection_established:
return
self._connection_established = True
self._reply(
p,
flags="A",
ack=uint32(p[TCP].seq + 1),
seq=uint32(self._isn + 1),
)
# Отправляем полезную нагрузку.
self._reply(
p,
create_http_response(
"Hello from the split handshake TCP server (4-way)!"
),
flags="PA", # PSH-ACK
ack=uint32(p[TCP].seq + 1),
seq=uint32(self._isn + 1),
)
После приёма сегмента с флагом SYN сервер шлёт два сегмента подряд: сегмент с флагом ACK, содержащее ISN клиента + 1, и сегмент с флагом SYN, содержащее собственный ISN. Когда мы получим ACK от клиента, считаем, что соединение установлено и, в целях простоты, не ожидая HTTP-запроса, сразу шлём HTTP-ответ.
Пробуем запустить. Не работает… клиент не получает наш payload. Взглянем на (упрощённые мной) логи tcpdump:
client > server: Flags [S], seq 778074755
server > client: Flags [A], ack 778074756
server > client: Flags [S], seq 1811503747
client > server: Flags [SA], seq 778074755, ack 1811503748
# Далее идут повторные переотправки из-за того, что не пришло ACK - подтверждение получения сегмента сервером.
client > server: Flags [SA], seq 778074755, ack 1811503748
client > server: Flags [SA], seq 778074755, ack 1811503748
client > server: Flags [SA], seq 778074755, ack 1811503748
client > server: Flags [SA], seq 778074755, ack 1811503748
Или, схематично:
Клиент Сервер
1. SYN -->
2. ACK <--
3. SYN <--
4. SYN,ACK -->
4. SYN,ACK -->
4. SYN,ACK -->
4. SYN,ACK -->
4. SYN,ACK -->
После приёма сегментов ACK и SYN от сервера, клиент отправляет сегмент SYN-ACK, как если бы сервер производил активное подключение! В некотором смысле, стороны поменялись ролями, как если бы сегмент SYN от клиента не был отправлен и сервер был клиентом и наоборот.
Получив сегмент SYN клиент отправляет ISN сервера + 1 и повторно отправляет свой ISN. Что ж, начиная с сегмента SYN от сервера, всё выглядит как 3-way handshake (начиная с сегмента #3 в схеме). Подыграем клиенту и ответим ACK на SYN-ACK:
elif fs == { "S", "A" }: # SYN-ACK
self._reply(
p,
flags="A",
ack=uint32(p[TCP].seq + 1),
seq=uint32(self._isn + 1),
)
# Отправляем полезную нагрузку.
self._reply(
p,
create_http_response(
"Hello from the split handshake TCP server (5-way)!"
),
flags="PA", # PSH-ACK
ack=uint32(p[TCP].seq + 1),
seq=uint32(self._isn + 1),
)
Теперь curl подключается и успешно получает наш HTTP-ответ. Давайте также попробуем подключиться из браузера. Открываем URL http://localhost:8000:
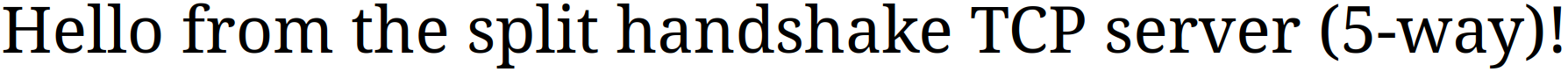
Таким образом получилось рукопожатие из 5 сегментов. Схема, по которой сейчас происходит установка соединения:
Клиент Сервер
1. SYN -->
2. ACK <--
3. SYN <--
4. SYN,ACK -->
5. ACK <--
Данный способ установки соединения называется разделённое рукопожатие (split handshake), потому что мы разделяем сегмент SYN-ACK на два. Ещё раз подчерну, что этот способ не описан в спецификации и со стороны сервера является не соответствующим спецификации, однако на практике таким образом можно установить TCP-соединение.
Согласно RFC 9293, в последовательности сегментов пятистороннего разделённого рукопожатия, сегмент #2 (ACK) является для клиента корректным, однако после всех обработок, он просто отбрасывается. Следовательно, можно отправить ноль и более сегментов ACK и получить рабочее рукопожатие. Реализуем каноническую версию, которая не отправляет ACK:
def handle_packet(self, p: Packet) -> None:
fs = set(p[TCP].flags)
if fs == { "S" }:
self._isn = random.randint(0, 2**32 - 1)
self._reply(p, flags="S", seq=self._isn)
elif fs == { "S", "A" }:
self._reply(
p,
flags="A",
ack=uint32(p[TCP].seq + 1),
seq=uint32(self._isn + 1),
)
self._reply(
p,
create_http_response(
"Hello from the split handshake TCP server (4-way)!"
),
flags="PA",
ack=uint32(p[TCP].seq + 1),
seq=uint32(self._isn + 1),
)
Проверяем, всё ли работает:
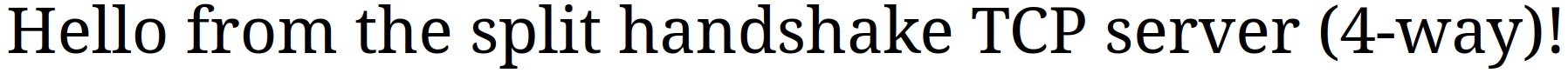
Теперь мы получили ещё один способ установки соединения из четырёх сегментов:
Клиент Сервер
1. SYN -->
2. SYN <--
3. SYN,ACK -->
4. ACK <--
Согласно первоисточнику [1], оба рассмотренных варианта с четырьмя и пятью сегментами называются разделённым рукопожатием. Пятистороннему варианту подходит данное название, ведь сегмент SYN-ACK был разделён на два. Четырёхстороннему варианту данное название подходит уже в меньшей степени, но всё же именуется он именно так.
В чём отличие данного варианта от трёхстороннего и одновременного открытия соединения? Отличие в том, что разделённое рукопожатие сочетает элементы одновременного открытия и трёхстороннего рукопожатия: начало (SYN-SYN) — как в первом случае, а завершение SYN, SYN-ACK, ACK — как во втором.
По сути, отправленный сервером сегмент SYN заставляет клиента игнорировать ранее отправленный им же самим сегмент SYN, что приводит к «перевороту» процесса подключения. Начиная с этого сегмента процесс выглядит как трёхстороннее рукопожатие, в котором сервер и клиент поменялись местами.
После обнаружения данного феномена было проведено тестирование ряда фаерволов и систем обнаружения вторжений. Некоторые из них вовсе не распознавали такую последовательность сегментов, как установку соединения. Другие неверно определяли роли сторон, принимая сервер за клиента, а клиента — за сервер, вследствие чего логика «ожидать возможного вредоносного поведения от клиента, а не от сервера» позволяла замаскировать трафик, идущий от клиента к контроллируемому взломщиком серверу. [1]
Источники Ссылка на заголовок
- Macrothink Institute: The TCP Split Handshake: Practical Effects on Modern Network Equipment.
- Stevens, Richard. TCP/IP Illustrated, Volume 1: The Protocols.
- LWN.net Weekly Edition for October 13, 2022: Fingerprinting systems with TCP source-port selection
- The CloudFlare blog: connect() - why are you so slow?
- Linux kernel source tree: tcp/dccp: better use of ephemeral ports in connect()